
In today's fast-paced business landscape, staying ahead of the competition requires efficient and effective solutions. According to Microsoft’s Work Trend Index, nearly 70% of employee report that they don’t have sufficient time in the day to focus on “work”, with more time being spent Communicating than Creating.
Microsoft 365 Copilot is designed, with Microsoft’s cloud trust platform at its core, to allow for employees to both be more productive, reduce the time spent searching for information, performing mundane tasks, and other low-value activities.

Azure SQL Data Warehouse is a fully managed, elastic data warehouse-as-a-service for processing enterprise workloads.
It is designed to efficiently scale up within minutes and grow to meet business needs. Azure SQL Data Warehouse is an integral component of Microsoft’s Cortana Intelligence Suite – a suite of services for big data storage and advanced analytics.
The architecture behind Azure SQL Data Warehouse takes a divide and conquer approach for large distributed datasets. Azure SQL Data Warehouse compute resources can be paused and resumed on-demand to eliminate costs during non-business hours. Familiar tools (such as Visual Studio, SQL Server Management Studio, Power BI, and other Azure services) easily integrate with Azure SQL Data Warehouse.
What is Data Warehousing?
"Data warehousing is the process of integrating multiple sources of data
into a central location for analysis and reporting across the enterprise."
Reporting from a data warehouse offloads queries from transactional systems. Queries executed in a data warehouse go across massive ranges of data and often return large data sets. This differs from traditional databases where small transactions handle inserts, updates, deletes and selects.
A data warehouse workload can consist of:
- Loading
- Managing
- Analyzing
- Reporting
- and Exporting data
Historical data can be analyzed to show trends in business operations or to facilitate planning and forecasting.
Azure SQL Data Warehouse Architecture
Before we consider the architecture of the Azure SQL Data Warehouse, let’s take a look at the architecture of a typical database server, such as SQL Server.
SQL Servers are implementations of symmetric multiprocessing (SMP). Each SMP system has multiple CPUs
to complete individual processes simultaneously.
All CPUs share the same resources of memory, disks, and network controllers.
To scale-up this type of system, more CPUs, memory, or disks are purchased and added to the tightly-coupled system.

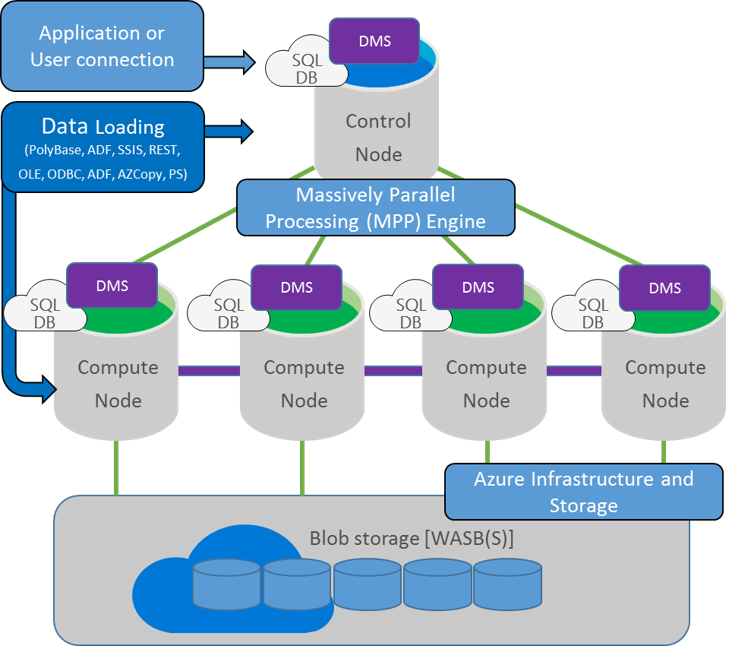
On the other hand, Azure SQL Data Warehouse is a massively parallel processing (MPP) implementation.
MPP system is broken down into four components:
- The MPP Engine
- Control Nodes
- Compute Nodes
- and Data Movement Service (DMS)
- The Control Node contains the MPP Engine that manages and optimizes queries.
- Each Compute Node is a server with a SQL Database that stores distributed parts of the full database. Compute Nodes have their own independent CPU, memory and storage resources implemented using the shared- nothing architecture.
- Data Movement Service quickly transports data between Control Node and Compute Nodes. Distributing the database across multiple nodes takes the divide and conquer approach to query very large
datasets .
(source)
 Want to learn more about Azure SQL Data Warehouse?
Want to learn more about Azure SQL Data Warehouse?
Check out our blog post:
"Azure SQL Data Warehouse
[Data Import Strategies]"