
In today's fast-paced business landscape, staying ahead of the competition requires efficient and effective solutions. According to Microsoft’s Work Trend Index, nearly 70% of employee report that they don’t have sufficient time in the day to focus on “work”, with more time being spent Communicating than Creating.
Microsoft 365 Copilot is designed, with Microsoft’s cloud trust platform at its core, to allow for employees to both be more productive, reduce the time spent searching for information, performing mundane tasks, and other low-value activities.
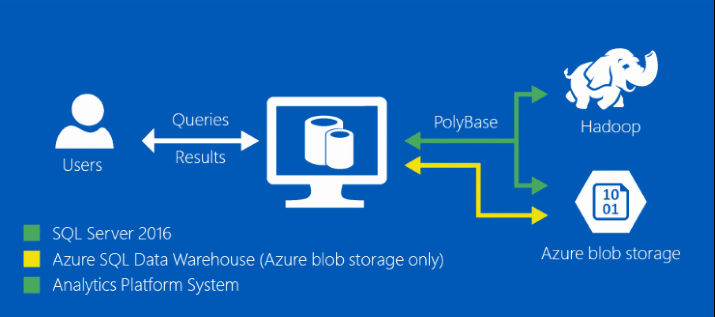
PolyBase is a Microsoft technology that can query Hadoop clusters or Azure Blob Storage. This is achieved by using T-SQL statements to import and export data between relational and non-relational data sources. While PolyBase is similar to Hive's HiveQL, Teradata's SQL-H, Apache Drill, Apache Sqoop, or Cloudera Impala it is different. With PolyBase, SQL Server Developers can use existing skills to query Hadoop. The need for SQL Server Developers to learn Hadoop or Linux is not required.
 *Source: https://msdn.microsoft.com/en-us/library/mt143171.aspx
*Source: https://msdn.microsoft.com/en-us/library/mt143171.aspx
*Source: https://msdn.microsoft.com/en-us/library/mt143171.aspxHistory
In the beginning, PolyBase was released with Microsoft's Parallel Data Warehouse (PDW) appliance. The current Microsoft appliance is called Analytics Platform System (APS). These appliances use massively parallel processing (MPP) architectures to create high performance and scalability systems. They are built with multiple servers operating self-sufficiently and control over its memory and disk. This is called a shared-nothing architecture. These systems are more expensive than traditional database servers. PDW and APS have used PolyBase to query Hadoop and other distributed computing systems. This technology is now available with SQL Server 2016.

Performance Improvements
PolyBase and the SQL Server query optimizer will push the computation to Hadoop to increase performance. It uses statistics on the external tables to determine when to leverage Hadoop. With PolyBase a T-SQL statement can be executed and join on multiple MapReduce jobs. This is the benefit over previous solutions as the query engine handles the MapReduce translation. There is another feature of SQL Server 2016 to overcome bottlenecks by using scale-out groups. PolyBase Groups assign one SQL Server as a Head node to run the PolyBase engine and multiple other SQL Server instances to run as Compute nodes. Massive data sets can be queried efficiently by splitting up the workloads to multiple instances. With SQL Server 2016 PolyBase Groups is an Enterprise edition feature, and only Compute node is available for Standard edition.
Big Data Extract, Transform, and Load
Using PolyBase and Columnstore Indexes within a Data Warehouse increase analytic processing by having the proper technologies do what they do best. Store massive data sets in on-premise Hadoop or Azure HDInsight. Execute PolyBase queries to process the data. Those results can then be inserted into a table with a Columnstore index. This analytic ETL solution provides distributed computation and a gain of 10x query performance for reporting.
PolyBase and Azure Blob Storage
Azure Storage is a significant cost savings solution for large datasets. Azure Blob Storage is specialized for handling structured and unstructured data as blobs. Azure Blob storage is cost-effective (see additional pricing details). These storage containers can be scaled up as needed to 500 TB. PolyBase is also able to access Azure Blob storage. This is a great solution for large batch analysis of log files, images, large text documents, social data, or device data with one query. If high throughput is required for accessing Azure Blob storage, one solution is to use Azure ExpressRoute. This will create a private connection between Azure datacenters and your on-premise sites.
Run a PolyBase example query
SQL Server 2016 PolyBase requires Java SE Run Time version 7.51 or higher (64-bit). TCP/IP connectivity must be enabled for communicating remotely to Azure. The following code demonstrates how to set up a connection to a publicly available Azure Blob storage.
SQL Server 2016 with PolyBase enables enterprise-ready data analytics. The combination of tested and proven SQL Server engine with the distributed computing power of Hadoop will allow enterprise access to analyzing all types of data from within SQL Server. Existing SQL skill sets can be used, and the need to learn new technology is not required.
Additional links to get started with PolyBase can be found below.
SQL Server 2016 Developer Edition
https://www.microsoft.com/en-us/cloud-platform/sql-server-editions-developers
PolyBase installation
https://msdn.microsoft.com/en-us/library/mt652312.aspx
Get started with PolyBase
https://msdn.microsoft.com/en-us/library/mt163689.aspx
Azure SQL Data Warehouse and PolyBase
https://github.com/Azure/azure-content/blob/master/articles/sql-data-warehouse/sql-data-warehouse-get-started-load-with-polybase.md
Have thoughts on this subject? Please comment below.